This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Customers can choose either of two approaches: Azure Stack HCI hardware-as-a-service, in which the hardware and software are pre-installed. Or, an enterprise can buy validated nodes and assume the responsibility for acquiring, sizing and deploying the underlying hardware. In addition, all storage is pooled.
In DisasterRecovery Planning, Don’t Neglect Home Site Restoration. In DisasterRecovery Planning, Don’t Neglect Home Site Restoration. Michelle Ziperstein is the Marketing Communications Specialist at Cervalis LLC , which provides data backup and disasterrecovery solutions for mission-critical data.
Equally, it is a focus of IT operational duties including workload provisioning, backup and disasterrecovery. Those resources are probably better spent re-architecting applications to remove the need for virtual machines (VMs). However, switching to HCI is a capital expense decision.
The latest CrowdStrike outage highlighted the need for a disasterrecovery plan that can help organizations resume critical IT operations in case of emergencies. What is DisasterRecovery as a Service (DRaaS)? The vendor also must ensure regular replica updates according to the client's recovery point objectives.
And theyre very resource-intensiveAI is poised to grow power demand. AI is a transformative technology that requires a lot of power, dense computing, and fast networks, says Robert Beveridge, professor and technical manager at Carnegie Mellon Universitys AI Engineering Center. Why pursue certifications?
The Software Defined Data Center Meets DisasterRecovery. The Software Defined Data Center Meets DisasterRecovery. It also means the person managing the data center can more efficiently utilize resources while providing better service to the company. It must be hardware agnostic. Industry Perspectives.
Being prepared for a bad situation that might never happen is better than experiencing a disaster that catches you off-guard. Read this post to learn more about disasterrecovery and discover the best practices that you should apply to improve the protection of your data and IT environment. What is disasterrecovery?
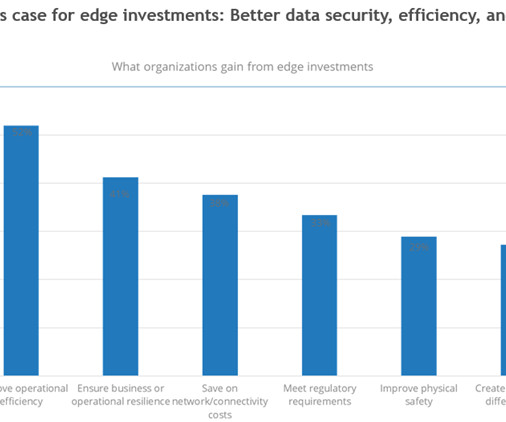
Hard costs include: Setting up the infrastructure (servers, connectivity, storage, gateways, sensors/input devices, and hardware) and integrating the edge deployment with it. The hardware required alone ranges from very basic to enterprise-class rack-based systems that consist of standalone, converged, or hyperconverged infrastructure.
Compact, scalable, and simple to manage, the all-in-one solution aggregated physical devices into an on-demand, fluid pool of resources. Intended to bring order to the administration of IT resources and to help companies get away from sprawling siloed storage solutions, HCI did more than that: it improved the experience of IT administration.
And there could be ancillary costs, such as the need for additional server hardware or data storage capacity. Here are some costs that will need to be included in your analysis: Hardware: Do I need to buy new hardware, or do I have capacity to run the software on existing servers and storage?
A workload repatriation report released by IDC in June found that 80% of companies expect to see some level of repatriation of compute and storage resources in the next 12 months. Other researchers are reporting similar trends. But “some” is the operative word. Fewer than 10% of companies had repatriated entire workloads.
One cloud computing solution is to deploy the platform as a means for disasterrecovery, business continuity, and extending the data center. Whether it is redundant hardware or a private hot-site, keeping an environment up and running 99.99% (insert more 9’s here) of the time is a tough job. By: Bill Kleyman July 23rd, 2013.
“Making sense” means a number of things here – understanding and remediating vulnerabilities, detecting and preventing threats, estimating risk to the business or mission, ensuring continuity of operations and disasterrecovery, and enforcing compliance to policies and standards. The first thing to do to manage events is to plan!
It can also improve business continuity and disasterrecovery and help avoid vendor lock-in. After all, an effective multicloud framework offers greater platform and service flexibility by leveraging the strengths of multiple cloud environments to drive business agility and innovation.
Mobile and embedded Agile environments – Proliferation of new device types, form factors, firmware and OS versions, and native hardware all present new complications for testers. Computing resources are allocated based on changing requirements in real time. Artificial Intelligence. Extended Cybersecurity. Internet of Things.
MSPs can also bundle in hardware, software, or cloud technology as part of their offerings. Overall, managed service providers aim to provide cost-effective, efficient services at a predictable cost to enable clients to focus their internal IT resources on more business-differentiating activities elsewhere in the tech stack.
Organizations can leverage the CoE to help various groups take advantage of features included with cloud services others in the enterprise are already using, such as backup and disasterrecovery services. With a traditional data center, companies buy and install hardware with workload peaks in mind, Hon says.
By being up front and learning about the technology, how it is supported, and the team resources, we can create a tight integration plan. What are the resources on the team? What is the overall IT ecosystem—infrastructure, architecture, integrations, disasterrecovery, data management, helpdesk, etc.? How is it governed?
But a complex web of fragmented software and hardware, including disparate management tools, infrastructure silos, and manual processes, is impeding transformational journeys. Business and IT leaders are well aware of the need for – and the benefits of – being data-driven as a key to their digital transformation success.
When it comes to infrastructure solutions, Dell offers a range of energy-efficient hardware options to help you build the most efficient infrastructure you can. Data center of the future: We’re actively working to leverage technology and innovation to design data centers that reduce resource consumption.
You know the drill: software licenses, subscription fees, consulting fees, and hardware infrastructure. The infrastructure supporting your AI systems also needs to evolve, requiring investments in scalability, redundancy, and disasterrecovery. Resources are finite, and pretending otherwise is a recipe for failure.
Shared Resources. These resources are shared with many users, and the hardware the cloud computing company provides is built on a system that makes the most efficient use of it. Even cloud computing in a small scale is worth taking a look at, as it allows access to much more powerful hardware than you would otherwise have.
The one huge lesson is there’s no bad side to planning to avert pushing the limits of technology capacity, workforce resiliency, and existing business continuity strategies and disasterrecovery planning. Continuously monitor utilization and uptime of applications, servers, and network resources. Something happens!
The deals are aimed at enabling customers to gain the benefits of Nutanix’s cloud platform without having to swap out the underlying server hardware or change server vendors. Changing customers’ minds one at a time can yield dividends, but convincing a partner OEM to put resources behind your product is a multiplier.” Pearson agrees.
Unlike traditional storage management, a cloud operational experience delivers the self-service storage provisioning agility that your LOB owners and developers need to accelerate app deployment while also freeing IT resources to work on strategic, higher-value initiatives. Put storage on autopilot with an AI-managed service.
It can then provision cloud resources, replicating and synchronizing the entire app stack (including operating system, kernel, app software stack, and app data) in the cloud site. Amazon has cut prices for dedicated EC2 instances – an instance on single-tenant hardware that is particularly attractive to enterprise customers.
This includes securing hardware, software, and sensitive data from unauthorized access and manipulation. Disasterrecovery and business continuity planning Effective disasterrecovery strategies are essential for maintaining operations during and after security incidents, ensuring minimal disruption.
It all depends on your particular business needs, on your resources, and the amount of risk you are ready to take. The user does not physically own or operate the servers but instead utilizes the Internet to access the computing resources. You do not have to buy and configure new hardware. The downside? Maintenance.
OS Manages Processes & Resources. OS Provides Portability (same app runs on different hardware). OS in 1960s • IBM OS/360 – First OS that kept track of system resources (program, memory, storage) • CTSS – Introduce scheduling • Univac Exec 8, Burrows MCP, Multics. Schedule Components & Resources.
Many companies have now transitioned to using clouds for access to IT resources such as servers and storage. The user level elements that are managed within such an IaaS cloud are virtual servers, cloud storage and shared resources such as load balancers and firewalls. DisasterRecovery. Cloud Management. Silicon Valley.
Amazon has cut prices for dedicated EC2 instances – an instance on single-tenant hardware that is particularly attractive to enterprise customers. DisasterRecovery. Featured Cloud Articles. Latest AWS Price Cuts Target the Enterprise & the Competition. Planning for a Cloud-Ready Distributed Storage Infrastructure.
The potential exists for significant savings as SDN allows data centers to move away from single source hardware to the commodity-based pricing we see with servers. 7) The organization’s access to personnel and capital resources. 2) The size of an organization’s network. The real drive behind SDN is workflow automation.
To remain profitable and competitive, organizations need to ensure that every resource is consumed economically and every asset utilized optimally. Amazon has cut prices for dedicated EC2 instances – an instance on single-tenant hardware that is particularly attractive to enterprise customers. DisasterRecovery.
Cloudsmith provides tools for system administrators and developers that make it easier to automate management of IT resources through intuitive GUIs and SaaS applications. Amazon has cut prices for dedicated EC2 instances – an instance on single-tenant hardware that is particularly attractive to enterprise customers. Convergence.
In our business where large CAD files have been moving toward a more collaborative parametric modeling data set, more resources for Granite Edge appliances make perfect sense. Amazon has cut prices for dedicated EC2 instances – an instance on single-tenant hardware that is particularly attractive to enterprise customers.
Recently the company has been working on movies such as “The Great Gatsby”, “Walking with Dinosaurs” for the BBC and “Iron Man 3″ With the demands of all of this computing power Animal Logic has had to look to its service provider Steam Engine for additional resources. DisasterRecovery.
The partnership matches Univa’s distributed resource management software platform with the MapR enterprise-grade big data platform. Univa Adds Intel Phi Support to Resource Management Platform. DisasterRecovery. ” RELATED POSTS: Big Data News: Intel, WalmartLabs, DataStax. . Featured Cloud Articles.
Are you tired of managing a sprawling IT infrastructure that consumes valuable resources and takes up too much space? By allowing multiple virtual servers to run on a single physical server, server virtualization enables businesses to maximize resource utilization, improve scalability, and simplify management.
The two data centers have been put in place to manage disasterrecovery, the company said. “Oracle EU Sovereign Cloud gives customers the services and capabilities of Oracle Cloud Infrastructure’s (OCI) public cloud regions with the same support, and service level agreements (SLAs) to run all workloads,” Oracle said in a statement.
of administrative tasks such as OS and database software patching, storage management, and implementing reliable backup and disasterrecovery solutions. pricing starts at $0.035/hour and is inclusive of SQL Server software, hardware, and Amazon RDS management capabilities. License Includedâ??
Like their counterparts in Europe, South African companies are increasingly mindful of resource constraints and the impact of fossil fuels on climate change,” said Singh. Silicon Sky has a vast IaaS portfolio including compute, network, storage, security, backup, recovery and disasterrecovery.
Tools for effective decision-making can improve the infrastructure and operations (I&O) team’s ability to allocate resources to the right types of activities. Amazon has cut prices for dedicated EC2 instances – an instance on single-tenant hardware that is particularly attractive to enterprise customers. Silicon Valley.
Both of these technologies instantly resulted in additional hardware on the motherboard: The Network Interface Card (NIC) for connection to Ethernet, etc., These pieces of hardware were sometimes incorporated into the motherboard itself, or sometimes were additional plug-ins. Presto - instant DisasterRecovery (DR).
They talked about how end users shouldn’t use their premier VDI solution XenDesktop as a disasterrecovery solution. This allows you to oversubscribe the physical virtual host with dozens of passive nodes depending on your application mix and hardware configuration. Your datacenter DR strategy leverage Cloud based resources?
We organize all of the trending information in your field so you don't have to. Join 83,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content