This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A reference architecture provides the full-stack hardware and software recommendations. The one thing that the reference architecture does not cover is storage, since Nvidia does not supply storage. However, there is another advantage, and that has to do with scale.
HiveIO Hive Fabric HiveIO is a Linux Kernel-based VM (KVM) that features an intelligent message bus, pool orchestration, user profile management, and shared storage. Customers can choose either of two approaches: Azure Stack HCI hardware-as-a-service, in which the hardware and software are pre-installed.
This software is installed on-premises and is responsible for copying data from servers, databases, and other devices to a storage system to safeguard it against loss or corruption. However, managing backup software can be complex and resource intensive. What is Backup as a Service (BaaS)?
While its still possible to run applications on bare metal, that approach doesnt fully optimize hardware utilization. With virtualization, one physical piece of hardware can be abstracted or virtualized to enable more workloads to run. CRDs allow Kubernetes to run different types of resources. What can you do with KubeVirt?
Businesses can pick their compute, storage and networking resources as needed, IBM stated. Scaling is achieved using a choice of numerous industry-standard and high-capacity Ethernet switches and other supporting infrastructure to help lower costs, IBM stated.
In estimating the cost of a large-scale VMware migration , Gartner cautions: VMwares server virtualization platform has become the point of integration for its customers across server, storage and network infrastructure in the data center. But, again, standalone hypervisors cant match VMware, particularly for storage management capabilities.
But it’s time for data centers and other organizations with large compute needs to consider hardware replacement as another option, some experts say. Power efficiency gains of new hardware can also give data centers and other organizations a power surplus to run AI workloads, Hormuth argues.
Rather than cobbling together separate components like a hypervisor, storage and networking, VergeOS integrates all of these functions into a single codebase. The software requires direct hardware access due to its low-level integration with physical resources. VergeFabric is one of those integrated elements.
Device spending, which will be more than double the size of data center spending, will largely be driven by replacements for the laptops, mobile phones, tablets and other hardware purchased during the work-from-home, study-from-home, entertain-at-home era of 2020 and 2021, Lovelock says. growth in device spending.
That doesnt necessarily mean that most enterprises are expanding the amount of cloud storage they need, he says. The Gartner folks are right in saying that there is continued inflation with IT costs on things such as storage, so companies are paying more for essentially the same storage this year than they were the year prior.
Core challenges for sovereign AI Resource constraints Developing and maintaining sovereign AI systems requires significant investments in infrastructure, including hardware (e.g., Many countries face challenges in acquiring or developing the necessary resources, particularly hardware and energy to support AI capabilities.
Open RAN (O-RAN) O-RAN is a wireless-industry initiative for designing and building 5G radio access networks using software-defined technology and general-purpose, vendor-neutral hardware. Enterprises can choose an appliance from a single vendor or install hardware-agnostic hyperconvergence software on white-box servers. Industry 4.0
The Singapore government is advancing a green data center strategy in response to rising demand for computing resources, driven in large part by resource-hungry AI projects. Singapore wants to go beyond that and reduce energy use for air-cooling by raising the temperatures at which servers and storage racks can safely operate.
Yet while data-driven modernization is a top priority , achieving it requires confronting a host of data storage challenges that slow you down: management complexity and silos, specialized tools, constant firefighting, complex procurement, and flat or declining IT budgets. Put storage on autopilot with an AI-managed service.
It is no secret that today’s data intensive analytics are stressing traditional storage systems. SSD) to bolster the performance of traditional storage platforms and support the ever-increasing IOPS and bandwidth requirements of their applications.
AI servers are advanced computing systems designed to handle complex, resource-intensive AI workloads. They also use non-volatile memory express (NVMe) storage and high-bandwidth memory (HBM). Workload determines configuration : The specific AI workloads you intend to run will dictate the necessary hardware configuration.
Adversaries that can afford storage costs can vacuum up encrypted communications or data sets right now. It can take money and personnel to fix encryption, and not all providers will have the resources or the interest in making it a priority. On the plus side, theres more than just customer demand forcing them to step up.
Blackwell will also allow enterprises with very deep pockets to set up AI factories, made up of integrated compute resources, storage, networking, workstations, software, and other pieces. But Nvidia’s many announcements during the conference didn’t address a handful of ongoing challenges on the hardware side of AI.
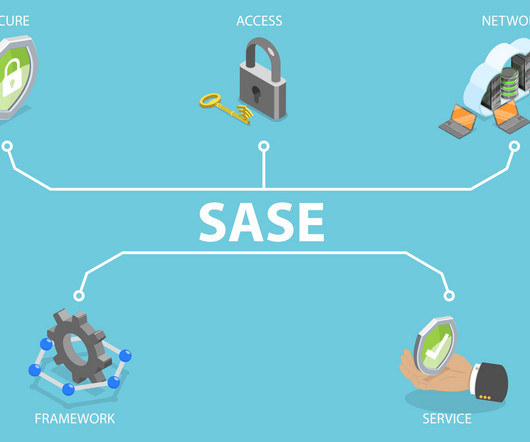
The key zero trust principle of least-privileged access says a user should be given access only to a specific IT resource the user is authorized to access, at the moment that user needs it, and nothing more. Secure any entity accessing any resource Plenty of people hear zero trust and assume its the same as zero trust network access (ZTNA).
This offers several benefits, including scalability, flexibility, and reduced hardware costs. ZTNA requires verification of every user and device before granting access to any resource, regardless of location. This is especially important for remote and mobile workers who need seamless access to cloud-based applications.
As data centers evolve from traditional compute and storage facilities into AI powerhouses, the demand for qualified professionals continues to grow exponentially and salaries are high. And theyre very resource-intensiveAI is poised to grow power demand. But its not all smooth sailing. Why pursue certifications?
One of the perennial problems of data centers is monitoring server utilization to ensure right-sizing of resources. Having too few resources can lead to overprovisioning, which can cause downtime as virtual machines become starved for compute, memory, and storage. Getting it just right takes skill - and a good set of tools.
MMA is a feature of Power10-based servers that handles matrix multiplication operations in hardware, rather than relying solely on software routines. The company added a Power Virtual Server Private Cloud features that lets customers better control and manage Power resources locally or in a hybrid cloud environment, according to IBM.
And this approach, in which IT can harness as-a-service IT resources via a cloud operational model from edge to core to cloud, is now essential to successful transformation. Modernizing primary storage is key to transformation. What’s needed is STaaS — for all. How to identify STaaS for all workloads.
For generative AI, a stubborn fact is that it consumes very large quantities of compute cycles, data storage, network bandwidth, electrical power, and air conditioning. In storage, the curve is similar, with growth from 5.7% of AI storage in 2022 to 30.5% Facts, it has been said, are stubborn things.
AI services require high resources like CPU/GPU and memory and hence cloud providers like Amazon AWS, Microsoft Azure and Google Cloud provide many AI services including features for genAI. Data processing costs: Track storage, retrieval and preprocessing costs.
The Indian Institute of Science (IISc) has announced a breakthrough in artificial intelligence hardware by developing a brain-inspired neuromorphic computing platform. The IISc team’s neuromorphic platform is designed to address some of the biggest challenges facing AI hardware today: energy consumption and computational inefficiency.
Cyberthreats, hardware failures, and human errors are constant risks that can disrupt business continuity. Predictive analytics allows systems to anticipate hardware failures, optimize storage management, and identify potential threats before they cause damage.
Meanwhile, enterprises are rapidly moving away from tape and other on-premises storage in favor of cloud object stores. Cost optimization: Tape-based infrastructure and VTL have heavy capital and operational costs for storage space, maintenance, and hardware.
IaaS is defined as the use of IT hardware and software infrastructure components like compute power or storage, utilized through the cloud in a flexible consumption or subscription-based model. Like SaaS, it is an all-inclusive category that can span the entire IT infrastructure portfolio from compute to storage to networks.
For these data to be utilized effectively, the right mix of skills, budget, and resources is necessary to derive the best outcomes. Computational requirements, such as the type of GenAI models, number of users, and data storage capacity, will affect this choice. An example is Dell Technologies Enterprise Data Management.
The challenge for many organizations is to scale real-time resources in a manner that reduces costs while increasing revenue. Match your server components to your use case: For the software supporting your database to achieve the best real-time performance at scale, you need the right server hardware as well.
Hard costs include: Setting up the infrastructure (servers, connectivity, storage, gateways, sensors/input devices, and hardware) and integrating the edge deployment with it. The hardware required alone ranges from very basic to enterprise-class rack-based systems that consist of standalone, converged, or hyperconverged infrastructure.
As a result, data scientists often spend too much time on IT operations tasks, like figuring out how to allocate computing resources, rather than actually creating and training data science models. These problems are exacerbated by a lack of hardware designed for ML use cases. IDC agrees. The promise of MLOps.
A little over a decade ago, HCI redefined what data storage solutions could be. Even though early platforms did little more than consolidate compute, storage, and networking components in a single chassis, the resulting hyperconverged node was revolutionary. cost savings with flexible, independent scaling of compute and storage.
As VMware has observed , “In simple terms, a DPU is a programable device with hardware acceleration as well as having an ARM CPU complex capable of processing data. By offloading data storage and optimizing the network, the DPU frees the CPU power for mission-critical applications. Generic APIs typically reveal a single entry-point.
When joining F5 , she reflected on her career and said, F5s evolution from hardware to software and SaaS mirrors my own professional journey and passion for transformation. > Her path has included stints at Align Technology, Nimble Storage, and Conga, where she was CIO from 2017-2021.She billion range.
The companies will also integrate elements of their hardware and software for example, allowing Motorola radios to dispatch drones from citywide Brinc 911 response drone networks. We have put a ton of resources, effort and time into making our drones with components sourced from the U.S. public safety agencies.
In a traditional environment, everyone must collaborate on building servers, storage, and networking equipment. For instance, if IT requires more processing or storage, the team needs to initiate a capital expenditure to purchase additional hardware. It’s not a simple task, given the ephemeral nature of cloud resources.
Data gravity creeps in generated data is kept on premises and AI training models remain in the cloud’; this causes escalating costs in the form of compute and storage, and increased latency in developer workflow. But over time, data sets and AI models grow more complex as companies seek greater accuracy from the models.
The logical progression from the virtualization of servers and storage in VSANs was hyperconvergence. By abstracting the three elements of storage, compute, and networking, data centers were promised limitless infrastructure control. Those facilities are effectively closed loops with limits created by physical resources.
To reach that understanding, enterprises, partners, and sellers should be able to collect and analyze fine-grained resource utilization data per virtual machine (VM) — and then leverage those insights to precisely determine the resources each VM needs to perform its job. Why is this so important? About Jenna Colleran.
Because LLMs consume significant computational resources as model parameters expand, consideration of where to allocate GenAI workloads is paramount. With the potential to incur high compute, storage, and data transfer fees running LLMs in a public cloud, the corporate datacenter has emerged as a sound option for controlling costs.
Among LCS’ major innovations is its Goods to Person (GTP) capability, also known as the Automated Storage and Retrieval System (AS/RS). It also alleviated space and resources constraints, improved inventory accuracy and efficiencies, and cut costs on labor, warehousing leasing, and transportation.
We organize all of the trending information in your field so you don't have to. Join 83,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content